模型部署
模型部署是把训练或微调后的模型发布为可被业务调用的服务,并围绕版本、资源、接口、监控、安全和回滚建立生产化运行机制。
显示更多
模型部署不是把模型文件放到服务器上运行这么简单。生产环境需要处理模型加载、依赖环境、GPU显存、并发、超时、版本、鉴权、监控、灰度和回滚等问题,尤其是大模型服务,部署成本和稳定性压力更高。
企业模型部署还要与业务系统、知识库、工具调用和权限体系集成。模型输出质量不仅取决于模型本身,也受提示词、上下文、检索结果、调用链路和监控反馈影响。
本页持续聚合模型部署、大模型上线、推理服务和 AI 平台发布实践,帮助读者从实验模型走向生产服务。
- 覆盖模型服务化、Kubernetes部署、推理框架、GPU资源、版本管理、灰度发布和监控告警
- 帮助区分模型训练、模型推理、模型部署和 LLMOps 的职责边界
- 适合正在上线大模型服务、企业知识库、智能客服、AI Agent 或行业模型应用的团队
- 关联 AI基础设施、GPU调度、MLOps 内容
- 重点关注资源需求、服务稳定性、调用安全、版本回滚和成本控制
模型部署需要模型加载、依赖环境、API服务、资源管理、弹性伸缩、版本管理、灰度发布、监控指标、日志审计、限流鉴权和回滚机制。大模型场景还要管理显存和调用成本。
典型流程包括模型注册、环境构建、部署配置、资源申请、接口验证、性能压测、灰度发布、监控观察和正式切流。每一步都应有可回滚和可审计记录。
常见风险包括依赖环境不一致、显存不足、延迟过高、并发能力不足、模型版本混乱、输出质量不可控和接口权限过大。部署前需要把技术风险和业务风险同时纳入检查。
学习路径
-
vLLM Kubernetes部署怎么做?配置GPU推理服务
想把 vLLM 从单机示例放到 Kubernetes 上运行,难点通常不在启动命令,而在 GPU、模型文件、服务访问和运行状态验证。这篇文章按部署链路拆解可参考的配置思路。
-
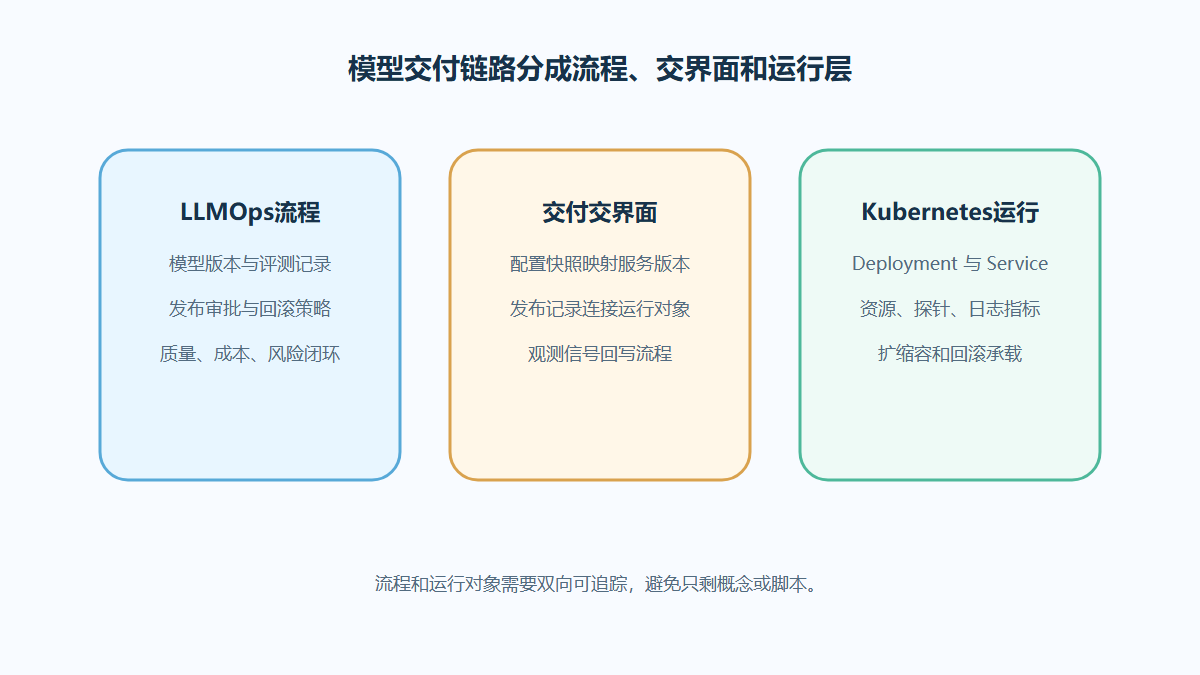
LLMOps Kubernetes模型交付链路设计
大模型上线不是把容器部署到集群就结束。围绕 LLMOps和Kubernetes 的分工,本文梳理模型从注册、发布、扩缩容到观测回滚的交付链路,让平台团队看清先补哪一段能力。
-
KServe vLLM区别怎么判断?服务层对比方法
纠结 KServe 和 vLLM 怎么选时,先别急着做二选一。一个更偏模型服务层,一个更偏推理执行层;读完本文可以用层级、职责和场景矩阵判断它们在平台中的位置。
-
GPU推理副本数设置怎么做?显存判断方法
GPU推理副本数设置容易被 QPS、显存和冷启动同时影响。本篇用单副本显存、并发拐点、GPU调度边界和上线验证流程,帮助团队先定保守初始值,再通过压测和真实流量校准。
-
大模型部署到K8s怎么做?资源镜像服务上线要点
把大模型服务搬到 Kubernetes 后,最容易卡在镜像拉取慢、GPU 不可见、模型文件加载和服务暴露上。本篇按资源、镜像、模型和服务四条线梳理上线步骤与检查项。
-
向量检索服务怎么部署?索引、存储与可观测性
向量检索服务上线后,问题往往出在索引更新、召回延迟、存储增长和权限边界上。把索引、数据、服务和观测一起设计,才能支撑稳定的 RAG 与语义检索应用。
-
模型注册中心怎么建设?元数据、权限与生命周期
模型文件越来越多时,团队最先遇到的问题不是存储空间,而是谁能使用、哪个版本可信、能否发布、出了问题能否追溯。模型注册中心把这些信息组织成可管理的生命周期。
-
模型评测流水线怎么搭建?离线指标与线上反馈
模型能不能上线,不能只看一次离线分数。评测流水线需要把样本、指标、版本、业务反馈和发布决策连接起来,让每次模型变化都有可比较、可追溯的依据。
-
LLMOps平台要具备哪些能力?提示词、评测与发布治理
大模型应用上线后,变化的不只是模型文件,提示词、工具调用、知识库、评测集和路由策略都会影响结果。LLMOps 平台要把这些变化纳入可测试、可发布、可回滚的流程。
-
AI推理网关怎么设计?路由、鉴权与配额治理
当模型数量和调用方增加后,直接暴露推理服务会让鉴权、路由、限流和观测分散在各处。AI 推理网关把调用入口统一起来,让多模型服务具备更清晰的治理边界。
-
在线推理和离线推理有什么区别?架构与资源对比
在线推理和离线推理都在执行模型,但架构目标完全不同。在线推理关注低延迟、稳定性和弹性,离线推理更看重吞吐、批处理和成本效率。区分两者的资源和治理方式,有助于避免用同一套平台策略处理不同任务。
-
模型版本管理怎么做?从实验产物到发布记录
模型版本管理不只是给文件起编号,而是记录模型从实验、评估、部署到回滚的完整上下文。训练数据、指标结果、镜像配置和发布记录串起来,团队才能解释某个线上版本从哪里来、为什么上线、出了问题如何恢复。
-
推理服务观测看什么?延迟、吞吐与结果质量
推理服务观测不能只看服务是否存活。延迟、吞吐、错误率、资源水位能反映系统稳定性,输出分布、置信度和关键样本能反映模型结果质量。把两类指标结合起来,才能判断服务是否真正可用。
-
模型回滚为什么不只是切文件?配置与特征一致性
模型回滚如果只切回旧模型文件,仍可能因为镜像、配置、特征逻辑、路由规则或依赖版本不一致而失败。真正可靠的回滚,需要恢复一组可运行上下文,让模型结果和服务行为同时回到可验证状态。
-
多模型部署如何治理?资源隔离、路由与版本边界
多模型共用同一平台后,难点会从“能否部署”转向资源隔离、版本边界、路由规则和故障影响范围。提前设计租户、资源池和模型版本关系,可以避免一个模型的流量、显存或配置问题影响整个平台。
-
模型上线为什么会失败?环境、依赖与资源问题
模型离线评估通过,不代表上线一定稳定。环境差异、依赖版本、输入输出格式、资源配置和超时策略都会让模型在生产中失败。把这些问题前置检查,可以减少“实验能跑、线上不可用”的发布风险。
-
模型服务化怎么做?接口、版本与观测能力
模型服务化的关键,不是把推理脚本包成一个接口,而是让模型具备稳定调用、版本管理、流量治理和运行观测能力。把接口、版本和指标设计清楚,模型才能从实验产物变成可持续运维的在线服务。
-
模型推理延迟高怎么排查?从路由到资源水位
推理服务延迟升高时,问题可能出在请求路由、批处理窗口、模型冷启动、显存水位或下游依赖,而不一定是模型本身变慢。按链路拆解延迟来源,可以帮助平台团队更快区分是服务容量、资源调度还是模型运行时问题。
-
模型部署平台需要哪些能力?版本、路由与观测
评估模型部署平台时,不能只看是否能启动一个推理服务。版本管理、流量路由、资源调度、灰度回滚和观测能力,决定了模型能否持续稳定地进入生产。
-
模型灰度发布怎么做?流量切分与回滚策略
新模型上线前,需要先把风险控制在小范围流量中。围绕流量切分、指标对比和回滚预案建立灰度流程,可以避免模型效果和系统稳定性问题在全量发布后才暴露。



















了解更多关于模型部署的信息
模型部署和模型推理有什么区别?
模型部署强调把模型发布到目标环境并形成可运行服务,包括环境、资源、版本、接口和发布流程;模型推理强调模型在运行时处理请求并输出结果,更关注延迟、吞吐、并发和成本。
两者关系紧密。没有稳定部署,推理服务无法可靠运行;没有推理性能和监控,部署也无法证明生产可用。企业通常需要把部署和推理作为同一条生产链路设计。
大模型部署为什么比普通模型更复杂?
大模型通常需要更多 GPU 显存、更复杂的推理框架、更高的并发控制和更严格的成本管理。上下文长度、批处理、量化、缓存和流式输出都会影响部署架构。
同时,大模型应用往往还连接知识库、工具调用和业务权限,输出质量也需要持续评估。部署不只是技术上线,还包括安全、审计和业务风险控制。
模型部署是否一定要用Kubernetes?
不一定。少量模型或试验场景可以使用简单服务、虚拟机或托管平台。但当模型数量增加、需要弹性伸缩、GPU资源治理、多团队协作和统一监控时,Kubernetes 或云原生平台会更适合。
选择 Kubernetes 的前提是团队具备平台运维能力。否则,Kubernetes 的复杂度可能抵消模型部署自动化带来的收益。企业应按规模和成熟度选择部署方式。
模型部署上线前应该做哪些验证?
至少要验证接口功能、输入输出边界、资源占用、延迟吞吐、错误处理、日志监控、鉴权权限、灰度策略和回滚方案。涉及敏感数据时,还要验证数据脱敏、审计和合规要求。
不要只用单次请求成功判断模型可以上线。生产流量会带来并发、异常输入、上游依赖波动和资源竞争,必须通过压测和灰度观察确认服务稳定。
模型部署如何控制成本?
成本控制可以从模型大小、资源规格、量化、批处理、缓存、弹性伸缩、请求路由和模型分层入手。不是所有请求都需要调用最大模型,也不是所有服务都需要长期占用高价值 GPU。
平台还需要成本归因,把资源消耗关联到模型、项目、团队和业务场景。只有知道成本流向,才能判断优化模型、调整架构还是扩容资源更合理。
模型部署后如何持续治理?
部署后需要持续监控延迟、错误率、资源利用率、调用量、成本、输出质量和用户反馈。模型服务不是一次上线后就结束,它会受到数据变化、业务变化和依赖变化影响。
成熟团队会把模型版本、提示词、知识库、调用链路和业务指标关联起来,形成问题定位和持续优化闭环。否则模型效果下降时,很难判断问题来自哪里。